本文章由likeog发布在公众号逆向工程入门到入院。请关注公众号。
什么是数组?相同类型的数据的集合。
所以当我们有一些相同类型的数据需要放到一起的时候,就可以使用数组,以方便对其操作。
void func()
{
//类型 数组名称[数量] = {赋值}
//分别测试一下char类型的数组占据几个字节
char arr[4]={0};
char arr[3]={0};
}
int main()
{
func();
return 0;
}
上面是一个数组声明,我们观察一下反汇编。
00401060 55 push ebp
00401061 8B EC mov ebp,esp
00401063 83 EC 44 sub esp,44h
00401066 53 push ebx
00401067 56 push esi
00401068 57 push edi
00401069 8D 7D BC lea edi,[ebp-44h]
0040106C B9 11 00 00 00 mov ecx,11h
00401071 B8 CC CC CC CC mov eax,0CCCCCCCCh
00401076 F3 AB rep stos dword ptr [edi]
10: char arr[4] = {0};
00401078 C6 45 FC 00 mov byte ptr [ebp-4],0
0040107C 33 C0 xor eax,eax
0040107E 66 89 45 FD mov word ptr [ebp-3],ax
00401082 88 45 FF mov byte ptr [ebp-1],al
11: }注意第三句,堆栈提升的时候。sub esp,0x44h。说明多给了数组四个字节(默认是sub esp,0x40h,大家忘了的话请复习前文)。现在有这样一个问题,既然每个char对应一个字节,是不是意味着单独会为每个char分配一个空间呢?比如char arr[3],会不会只占用3个字节?
00401060 55 push ebp
00401061 8B EC mov ebp,esp
00401063 83 EC 44 sub esp,44h
00401066 53 push ebx
00401067 56 push esi
00401068 57 push edi
00401069 8D 7D BC lea edi,[ebp-44h]
0040106C B9 11 00 00 00 mov ecx,11h
00401071 B8 CC CC CC CC mov eax,0CCCCCCCCh
00401076 F3 AB rep stos dword ptr [edi]
10: char arr[3] = {0};
00401078 C6 45 FC 00 mov byte ptr [ebp-4],0
0040107C 33 C0 xor eax,eax
0040107E 66 89 45 FD mov word ptr [ebp-3],ax
11: }
同样是sup,0x44h。为啥呢?咋不是0x43呢?这涉及之前提过的一个问题:内存对齐。实际上无论数组或非数组,存储数据都要考虑内存对齐。在32位的系统中,以4个字节单位。因为数据宽度与本机宽度一致时,运行效率最高。 关于内存对齐,在后面结构体一节会详细阐述。
数组的存储
#include "stdafx.h"
void function(){
int arr[5]={1,2,3,4,5};
}
int main(int argc, char* argv[])
{
function();
return 0;
}反汇编如下:
8: int arr[5]={1,2,3,4,5};
0040D498 mov dword ptr [ebp-14h],1
0040D49F mov dword ptr [ebp-10h],2
0040D4A6 mov dword ptr [ebp-0Ch],3
0040D4AD mov dword ptr [ebp-8],4
0040D4B4 mov dword ptr [ebp-4],5
9: }可以看出数组的元素是从ebp-4的地方开始连续顺序存储。
数组的寻址
在汇编中,如何访问数组的成员呢?换句话说,就是如何寻址。
如果直接从C语言理解,是用数组的索引来进行访问。我们通过反汇编来看一下背后实际的寻址方式。
#include "stdafx.h"
void function(){
int x=1;
int y=2;
int res=0;
int arr[5]={1,2,3,4,5};
res=arr[1];
res=arr[x];
res=arr[x+y];
res=arr[x*2+y];
}
int main(int argc, char* argv[])
{
function();
return 0;
}反汇编为:
8: int x=1;
0040D498 mov dword ptr [ebp-4],1
9: int y=2;
0040D49F mov dword ptr [ebp-8],2
10: int res=0;
0040D4A6 mov dword ptr [ebp-0Ch],0
11: int arr[5]={1,2,3,4,5};
0040D4AD mov dword ptr [ebp-20h],1
0040D4B4 mov dword ptr [ebp-1Ch],2
0040D4BB mov dword ptr [ebp-18h],3
0040D4C2 mov dword ptr [ebp-14h],4
0040D4C9 mov dword ptr [ebp-10h],5
12: res=arr[1];
0040D4D0 mov eax,dword ptr [ebp-1Ch]
0040D4D3 mov dword ptr [ebp-0Ch],eax
13: res=arr[x];
0040D4D6 mov ecx,dword ptr [ebp-4]
0040D4D9 mov edx,dword ptr [ebp+ecx*4-20h]
0040D4DD mov dword ptr [ebp-0Ch],edx
14: res=arr[x+y];
0040D4E0 mov eax,dword ptr [ebp-4]
0040D4E3 add eax,dword ptr [ebp-8]
0040D4E6 mov ecx,dword ptr [ebp+eax*4-20h]
0040D4EA mov dword ptr [ebp-0Ch],ecx
15: res=arr[x*2+y];
0040D4ED mov edx,dword ptr [ebp-4]
0040D4F0 mov eax,dword ptr [ebp-8]
0040D4F3 lea ecx,[eax+edx*2]
0040D4F6 mov edx,dword ptr [ebp+ecx*4-20h]
0040D4FA mov dword ptr [ebp-0Ch],edx
16:
17: }我们简单记录一下变量的位置。
| 变量 | 值 | 地址 |
|---|---|---|
| x | 1 | ebp-4h |
| y | 2 | ebp-8h |
| res | 0 | ebp-0Ch |
下面仔细分析下四种寻址方式。
12: res=arr[1];
0040D4D0 mov eax,dword ptr [ebp-1Ch]
0040D4D3 mov dword ptr [ebp-0Ch],eax指定数组下标,编译器直接定位到位置,获取数据。
13: res=arr[x];
0040D4D6 mov ecx,dword ptr [ebp-4]
0040D4D9 mov edx,dword ptr [ebp+ecx*4-20h]
0040D4DD mov dword ptr [ebp-0Ch],edx当给定的数组下标为变量的时候。
- 变量x赋值给ecx寄存器
- ebp+ecx_4-20h 我们要拆分过来看。拆分成
ebp-20h,ecx*4两部分。ebp-20h是谁呢?数组arr的第一个成员。而ecx正是我们的变量x。为什么要乘4呢?因为数组arr的类型是int。如果short则是乘2。总而言之,先找到数组第一个成员,然后加上变量x_数组类型的偏移,即可得对应的数组成员。 - 把取的数据给变量res.
14: res=arr[x+y];
0040D4E0 mov eax,dword ptr [ebp-4]
0040D4E3 add eax,dword ptr [ebp-8]
0040D4E6 mov ecx,dword ptr [ebp+eax*4-20h]
0040D4EA mov dword ptr [ebp-0Ch],ecx还是一样,先计算数组下标的计算结果。将变量x赋值给eax寄存器后,使用add指令相加。最后用数组的首地址+变量*数组数据类型的偏移,取得对应的数组成员。
最后一个读者请自行分析。为什么会用lea取地址的指令呢?因为上面的例子中,使用add指令一次就可以获得偏移了。而表达式x*2+y,如果不用lea指令就需要两条指令,先使用乘法指令imul再add。那么这样的话无疑浪费了一条指令,编译器选择了最少的指令帮你解释,这也是编译器的优化。
数组越界
我们举两个例子来说明数组越界可能出现的问题。
#include <stdio.h>
#define SIZE 4
int main(void)
{
int value1 = 44;
int arr[SIZE];
int value2 = 88;
int i;
printf("value1 = %d,value2 = %d\n",value1,value2);
for(i = -1;i <= SIZE;i++)
arr[i] = 2*i + 1;
for(i = -1;i < 7;i++)
printf("%2d %d\n",i,arr[i]);
printf("value1 = %d,value2 = %d\n",value1,value2);
return 0;
}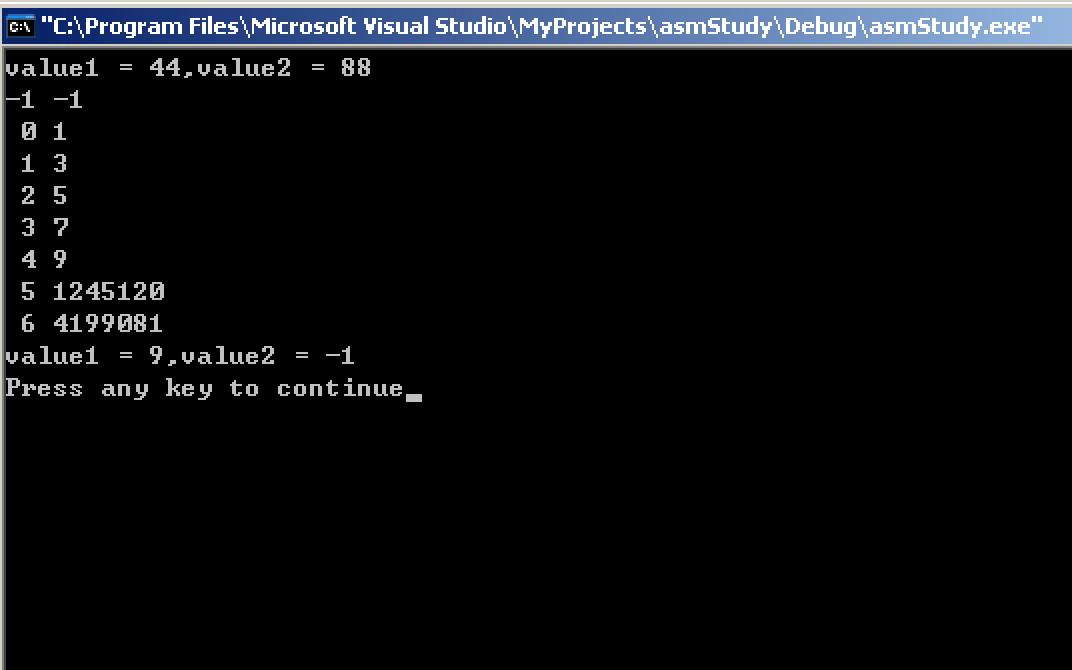
运行结果出人意料。事实上,数组一共只有5个元素(下标从0开始),赋值操作也进行了5次。而在显示数组数据的时候,我们使用了下标5和6。打印了并“不存在”的数据。
下面再看一个严重错误的例子。
#include "stdafx.h"
void fun(){
int arr[5]={1,2,3,4,5};
arr[6]=0x12345678;
}
int main(int argc, char* argv[])
{
fun();
return 0;
}
程序甚至无法正常运行。我们单步调试一下,从反汇编来看看端倪。
7: void fun(){
0040D790 55 push ebp
0040D791 8B EC mov ebp,esp
0040D793 83 EC 54 sub esp,54h
0040D796 53 push ebx
0040D797 56 push esi
0040D798 57 push edi
0040D799 8D 7D AC lea edi,[ebp-54h]
0040D79C B9 15 00 00 00 mov ecx,15h
0040D7A1 B8 CC CC CC CC mov eax,0CCCCCCCCh
0040D7A6 F3 AB rep stos dword ptr [edi]
8: int arr[5]={1,2,3,4,5};
0040D7A8 C7 45 EC 01 00 00 00 mov dword ptr [ebp-14h],1
0040D7AF C7 45 F0 02 00 00 00 mov dword ptr [ebp-10h],2
0040D7B6 C7 45 F4 03 00 00 00 mov dword ptr [ebp-0Ch],3
0040D7BD C7 45 F8 04 00 00 00 mov dword ptr [ebp-8],4
0040D7C4 C7 45 FC 05 00 00 00 mov dword ptr [ebp-4],5
9: arr[6]=0x12345678;
0040D7CB C7 45 04 78 56 34 12 mov dword ptr [ebp+4],12345678h
10: }单步调试,问题出在mov dword ptr [ebp+4],0x12345678h。在内存观察下ebp+4的值?
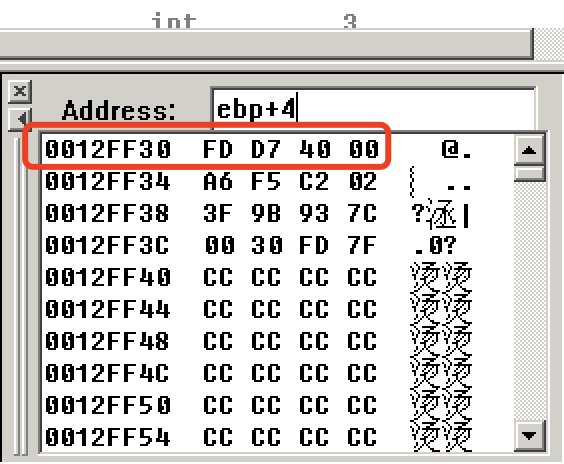
眼熟否?
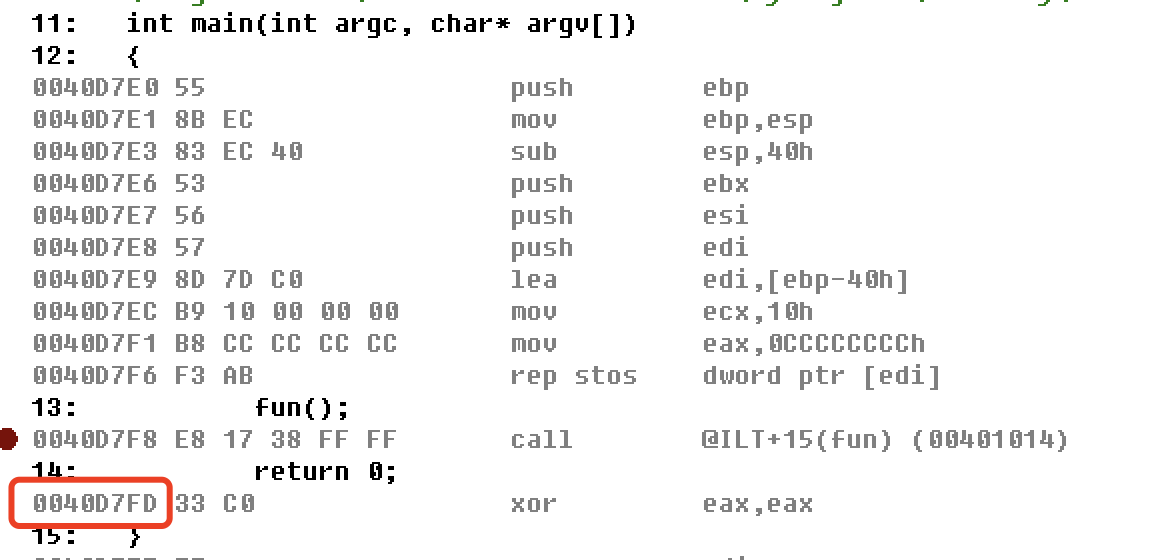
没错,fun函数的返回地址。你都给人家把返回地址给覆盖了。
利用数组越界(溢出)
先看这段代码。
#include "stdafx.h"
int addr;
void HelloWorld(){
printf("Hello World!\n");
__asm{
mov eax,addr
mov dword ptr [ebp+4],eax
}
}
void fun(){
int arr[5]={1,2,3,4,5};
__asm{
mov eax,dword ptr [ebp+4]
mov addr,eax
}
arr[6]=(int)HelloWorld;
}
int main(int argc, char* argv[])
{
fun();
__asm{
sub esp,4
}
return 0;
}我们来分析一下。
首先调用fun函数,进入后将当前函数的ebp+4,即返回地址备份到全局变量addr,随后把helloword的地址放入。
函数名即是函数地址。这样的话,执行完fun函数是不是就到helloworld函数啦?
执行完helloworld函数,在helloworld函数里将原备份的函数返回地址再赋值回来,这样能跳转到原本的返回地址。
注意,要平衡堆栈,所以要sub esp,0x4。
执行结果如下。
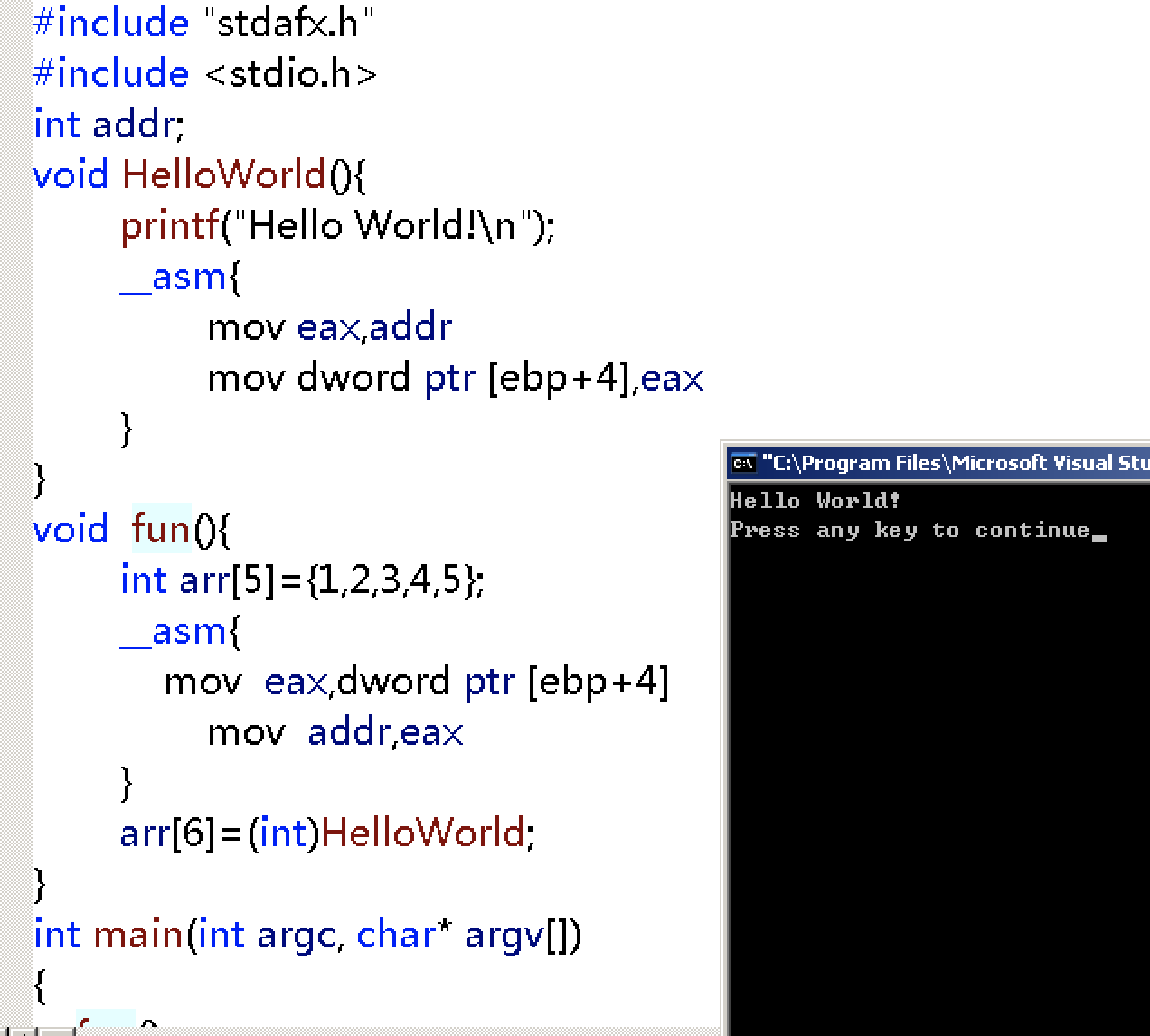

发表评论 取消回复